药物-药物相互作用 (DDI, Drug-Drug Interaction) 是指病人同时或在一定时间内先后服用两种或两种以上药物后会产生复合效应,既可能使药效加强或副作用减轻,也可能使药效减弱或出现毒副作用。
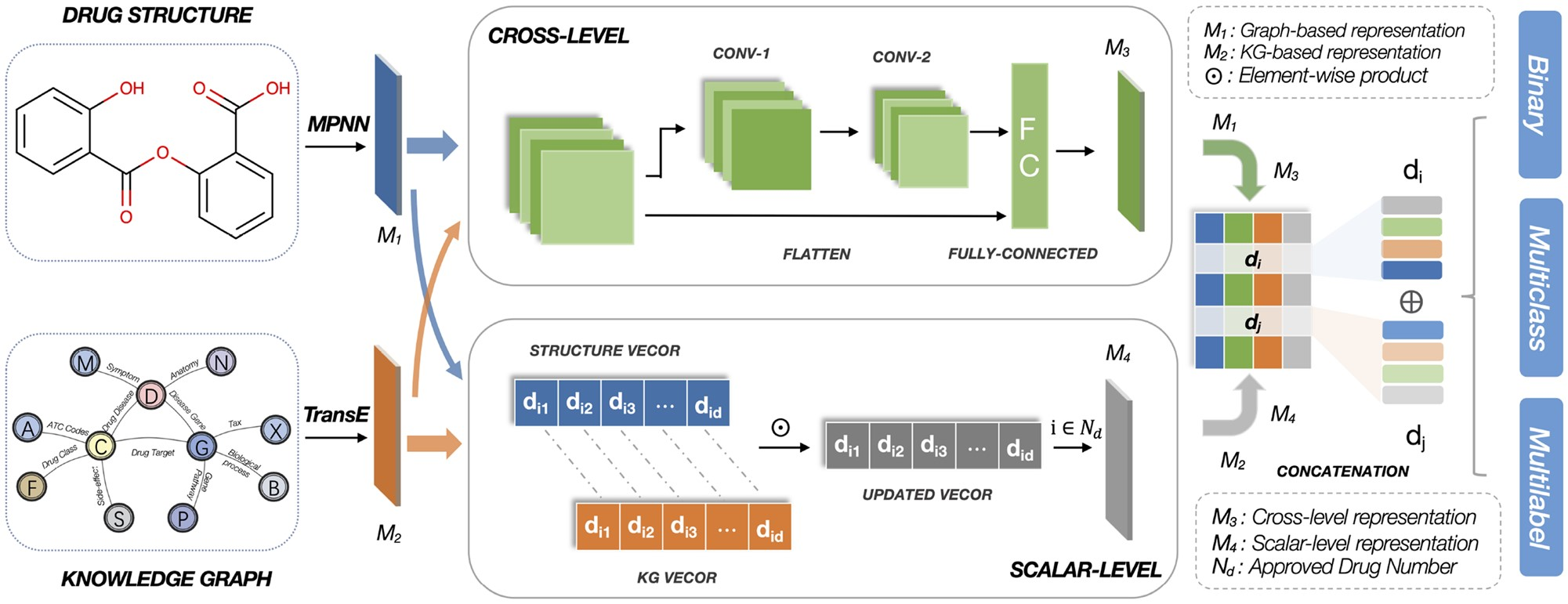
论文“MUFFIN: Multi-Scale Feature Fusion for Drug–Drug Interaction Prediction”旨在结合药物分子结构和生物医药知识图谱这两种不同视角的药物特征,以解决药物-药物相互作用预测问题。
数据预处理
针对原始药物特征数据,我们使用 DRKG 知识图谱以及DrugBank中的已批准药物的SMILES字符串。
获取DRKG知识图谱
# 只需要保留 “drkg.tsv” 文件 wget https://dgl-data.s3-us-west-2.amazonaws.com/dataset/DRKG/drkg.tar.gz
获取DrugBank中已批准药物及对应SMILES字符串
# 文件需要处理成如下格式:Compound::DB00119 CC(=O)C(O)=O https://go.drugbank.com/releases/5-1-8/downloads/approved-structure-links
处理数据为指定格式
训练药物-药物相互作用数据集,二分类和多分类数据集均来自于DrugBank
# 注:我们已经提供了默认使用的文件,您也可以按照如下代码自行处理 python data_process.py -s Your_Smiles_File_Path -kg Your_KG_File_Path -mc Your_Multi_Class_File_Path
加载数据
MUFFIN模型需要两部分药物特征,生成药物分子结构图的表征向量以及药物在知识图谱中的表征向量。
药物分子结构图的表征向量
# 生成 “gin_supervised_masking_embedding.npy” 文件 python pretrained_smiles_embedding.py -fi Your_Smiles_File_Path -m gin_supervised_masking -fo csv -sc smiles
药物知识图谱的表征向量
# 生成 “DRKG_TransE_l2_entity.npy” 文件 python pretrain_kg_embedding.py --model_name TransE_l2 --dataset DRKG --data_path data/DRKG/ --data_files entities.tsv relations.tsv train.tsv --format udd_hrt --batch_size 2048 --neg_sample_size 128 --hidden_dim 100 --gamma 12.0 --lr 0.1 --max_step 100000 --log_interval 1000 --batch_size_eval 16 -adv --regularization_coef 1.00E-07 --test --num_thread 1 --gpu 1 2 --num_proc 2 --neg_sample_size_eval 10000 --async_update
加载训练数据
import torch
import torch.utils.data as Data
data = DataLoaderMUFFIN(args, logging)
n_approved_drug = data.n_approved_drug
# 5-fold
for i in range(5):
train_x = torch.from_numpy(data.DDI_train_data_X[i])
train_y = torch.from_numpy(data.DDI_train_data_Y[i])
test_x = torch.from_numpy(data.DDI_test_data_X[i])
test_y = torch.from_numpy(data.DDI_test_data_Y[i])
torch_dataset_train = Data.TensorDataset(train_x, train_y)
torch_dataset_test = Data.TensorDataset(test_x, test_y)
loader_train = Data.DataLoader(
dataset=torch_dataset_train,
batch_size=args.DDI_batch_size,
shuffle=True
)
loader_test = Data.DataLoader(
dataset=torch_dataset_test,
batch_size=args.DDI_evaluate_size,
shuffle=True
)
data_idx = Data.TensorDataset(torch.LongTensor(range(n_approved_drug)))
loader_idx = Data.DataLoader(
dataset=data_idx,
batch_size=128,
shuffle=False
)模型定义
模型分为两个特征融合模块,其中包括cross-level以及scalar-level,其封装在muffinModel中。
model = muffinModel(args, entity_pre_embed, structure_pre_embed)
模型训练和评估
模型训练阶段核心代码
通过设定args.multi_type,可以指定运行二分类任务[False]还是多分类任务[True]
optimizer = optim.Adam(model.parameters(), lr=args.lr)
for epoch in range(1,args.n_epoch+1):
model.train()
ddi_total_loss = 0
n_ddi_batch = data.n_ddi_train[i] // args.DDI_batch_size + 1
for step, (batch_x, batch_y) in enumerate(loader_train):
out = model('calc_ddi_loss', batch_x, loader_idx)
if args.multi_type == 'False':
# 二分类
out = out.squeeze(-1)
loss = loss_func(out, batch_y.float())
else:
# 多分类
loss = loss_func(out, batch_y.long())
loss.backward()
optimizer.step()
optimizer.zero_grad()
ddi_total_loss += loss.item()
模型训练阶段核心代码
model.eval()
with torch.no_grad():
for data in loader_test:
test_x, test_y = data
out, all_embedding = model('predict', test_x, loader_idx)
acc_score, precision_score, recall_score, f1_score, auc_score = calc_metrics(test_y, prediction, out, args.multi_type)
模型训练之后,我们在测试集上进行结果评估,你可以获得如下类似结果。
5-fold cross validation DDI Mean Evaluation: Precision 0.9912 Recall 0.9913 F1 0.9912 ACC 0.9913 AUC 0.9994
完整模型训练
# 二分类任务 python main.py --—graph_embedding_file data/DRKG/gin_supervised_masking_embedding.npy --entity_embedding_file data/DRKG/DRKG_TransE_l2_entity.npy --multi_type False --out_dim 1 # 多分类任务 python main.py --—graph_embedding_file data/DRKG/gin_supervised_masking_embedding.npy --entity_embedding_file data/DRKG/DRKG_TransE_l2_entity.npy --multi_type True --out_dim 81
引用
如果您对我们的工作感兴趣或者使用了我们的代码,欢迎引用我们的工作:
@article{chen2021muffin,
title={MUFFIN: multi-scale feature fusion for drug--drug interaction prediction},
author={Chen, Yujie and Ma, Tengfei and Yang, Xixi and Wang, Jianmin and Song, Bosheng and Zeng, Xiangxiang},
journal={Bioinformatics},
year={2021}
}